Гіпотеза Крашена (Comprehensible Input): єдина наукова теорія вивчення мов, яка гарантує результат

Уявіть дитину, яка опинилася в іншій країні. Ніхто не дає їй підручників, не пояснює правила граматики, не змушує зубрити таблиці дієвідмін. Вона просто живе. Слухає. Дивиться. Читає вивіски. І через кілька місяців — вільно розмовляє. Це не магія. Це comprehensible input у дії — і це єдиний науково доведений механізм, через який людський мозок насправді засвоює мову.
Американський лінгвіст Стівен Крашен (Stephen Krashen) сформулював цю ідею ще у 1980-х, і з того часу вона витримала сотні перевірок, критику та тисячі досліджень. Висновок завжди один: мову неможливо «вивчити» — її можна лише «засвоїти», і єдиний шлях до цього — споживати зрозумілий контент, який трохи перевищує ваш поточний рівень.
Головне питання: як зробити будь-який текст зрозумілим? Ось тут починається найцікавіше.
Хто такий Стівен Крашен і чому його теорія змінила лінгвістику
Стівен Крашен — почесний професор Університету Південної Каліфорнії, один з найцитованіших лінгвістів у світі. Його роботи вплинули на освітні програми в десятках країн — від Тайваню до Швеції.
Крашен запропонував п'ять гіпотез засвоєння мови, але найвідомішою стала одна — Input Hypothesis (гіпотеза вхідного матеріалу). Суть проста як геніальність:
- Ми засвоюємо мову, коли розуміємо повідомлення, а не коли вивчаємо правила.
- Граматика «приходить сама», коли мозок отримує достатньо зрозумілого контексту.
- Зубріння правил та вправи не ведуть до вільного володіння — вони лише створюють ілюзію знання.
«We acquire language in one way — when we understand messages. We call this 'comprehensible input.'» — Stephen Krashen
Це означає, що кожна хвилина, проведена за зрозумілим текстом англійською, іспанською чи будь-якою іншою мовою, працює на ваше засвоєння ефективніше, ніж десятки годин граматичних вправ.
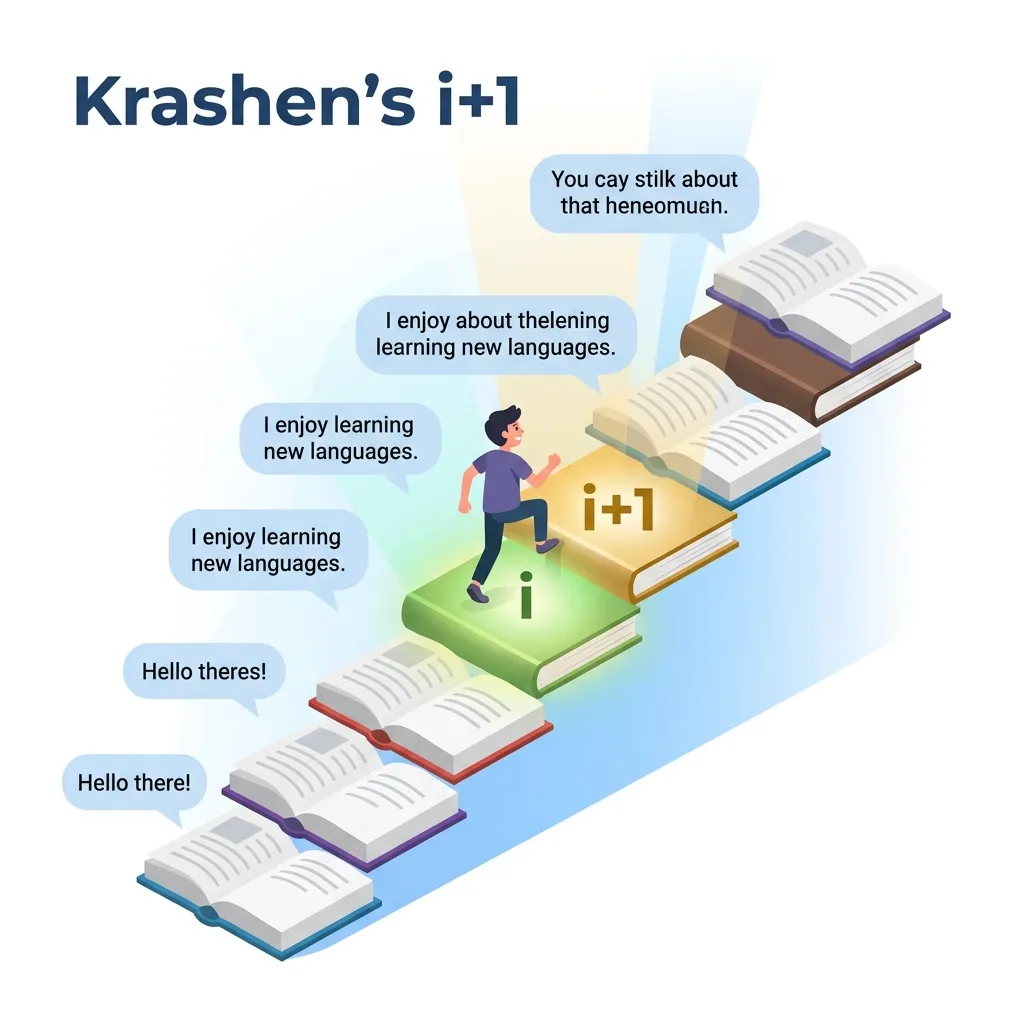
Формула i+1: магія рівня складності
Серце теорії Крашена — формула i+1, де:
- i — ваш поточний рівень мови
- +1 — трохи нового, невідомого матеріалу
Ідея в тому, що ідеальний навчальний матеріал має бути переважно зрозумілим (щоб мозок не панікував), але містити невелику кількість нового (щоб відбувалося засвоєння).
Чому це працює з точки зору нейронауки
Коли ви читаєте текст і розумієте 90-95% слів, ваш мозок автоматично вгадує значення невідомих 5-10% з контексту. Саме в цей момент формуються нові нейронні зв'язки. Це не свідоме зусилля — це підсвідомий, природний процес, ідентичний тому, як діти засвоюють рідну мову.
Проблема в тому, що знайти «ідеальний i+1» самостійно — майже неможливо:
- Занадто простий текст (i+0) = нудьга, нульовий прогрес
- Занадто складний текст (i+5) = фрустрація, мозок «вимикається»
- Ідеальний i+1 = потік, задоволення, стабільне зростання
Ось чому більшість людей застрягають: вони або нудьгують з підручниками рівня A2, або розбиваються об стіну оригінальної літератури. Між цими полюсами — пустеля.
П'ять гіпотез Крашена: повна картина
Input Hypothesis — це ядро, але Крашен побудував цілісну систему з п'яти взаємопов'язаних гіпотез.
1. Acquisition vs. Learning (засвоєння проти вивчення)
Це фундаментальне розмежування: засвоєння (acquisition) — підсвідомий процес, подібний до того, як діти «вбирають» рідну мову. Вивчення (learning) — свідоме запам'ятовування правил.
Крашен стверджує: тільки засвоєне знання веде до вільного, спонтанного мовлення. «Вивчене» ж може працювати лише як «редактор» — повільна свідома перевірка.
«Language acquisition does not require extensive use of conscious grammatical rules, and does not require tedious drill.» — Stephen Krashen
2. Monitor Hypothesis (гіпотеза монітора)
«Вивчені» правила працюють як внутрішній редактор — «монітор». Він перевіряє вашу мову на помилки, але тільки якщо є час, фокус на формі та знання правила. У живій розмові монітор практично безпорадний.
3. Natural Order Hypothesis (природний порядок)
Граматичні структури засвоюються в передбачуваній послідовності, і ця послідовність не залежить від порядку, в якому їх викладають у підручниках. Іншими словами, ваш мозок сам вирішує, що засвоювати першим — незалежно від навчальної програми.
4. Input Hypothesis (гіпотеза вхідного матеріалу)
Та сама формула i+1: ми просуваємося вперед, коли отримуємо мовний матеріал, який трохи перевищує наш поточний рівень. Ключове слово — «зрозумілий». Якщо input незрозумілий, він марний.
5. Affective Filter Hypothesis (афективний фільтр)
Стрес, тривога та страх помилки блокують засвоєння мови. Крашен називає це «афективним фільтром» — емоційним бар'єром, який не пропускає навіть ідеальний input до мовного центру мозку.
Це пояснює, чому люди роками ходять на курси, але не можуть заговорити. Стрес від оцінювання, страх перед групою, тривога на іспитах — все це піднімає афективний фільтр і блокує природне засвоєння.
Головна проблема: де взяти ідеальний comprehensible input
Теорія Крашена геніальна, але має одну практичну слабкість: де в реальному житті знайти контент рівня i+1?
Підручники — занадто штучні та нудні. Діалоги про «John and Mary go to the airport» не мотивують нікого.
Оригінальні книги та статті — занадто складні для більшості. Відкриваєш The Economist, зустрічаєш 30 невідомих слів на сторінку, і мотивація падає до нуля.
Адаптовані книги (graded readers) — обмежений вибір, стерильна мова, що не відповідає реальному вжитку.
Відео з субтитрами — чудово, але неможливо зупинити й розібрати кожну фразу.
Результат? Більшість людей знають про comprehensible input, але не мають інструменту, щоб його отримувати системно, щодня, з будь-яким контентом.
Як MovaReader перетворює БУДЬ-ЯКИЙ текст на ідеальний comprehensible input
MovaReader — це інструмент, який вирішує головну проблему гіпотези Крашена. Він не адаптує текст, не спрощує його, не вирізає складні слова. Він робить дещо розумніше: робить будь-який оригінальний текст на 100% зрозумілим, зберігаючи його автентичність.
Ось як це працює:
Миттєвий AI-переклад кожного слова та фрази
Зустріли незнайоме слово? Торкніться його — і отримайте не просто переклад, а повний контекстний аналіз: значення в даному реченні, альтернативні переклади, приклади вживання. Мозок миттєво отримує «+1» без фрустрації.
Уявіть, що ви читаєте статтю з The Guardian:
«The government's austerity measures have exacerbated inequality.»
Не знаєте «austerity» та «exacerbated»? Один дотик — і AI пояснює: «austerity — жорстка економія, урізання витрат», «exacerbated — загострив, погіршив». Ви зрозуміли речення, контекст зафіксувався в пам'яті — і прогрес відбувся.
English-to-English пояснення
Це кілер-фіча для тих, хто хоче думати англійською. AI пояснює складне слово простішими англійськими словами, без перекладу рідною мовою. Це чистий i+1 у його найефективнішій формі — ви розширюєте словниковий запас всередині цільової мови.
Аналіз структури речення
Складне багатоскладне речення більше не лякає. MovaReader розбирає його на складові: підмет, присудок, додаток, підрядні речення — з поясненням ролі кожного елемента. Граматика засвоюється через контекст, саме так, як описує Крашен.
Озвучка з AI-вимовою
Читаєте та одночасно чуєте правильну вимову. Це подвійний input — візуальний та аудіальний, що подвоює ефективність засвоєння.
Чому традиційні методи програють comprehensible input
Порівняємо підходи:
| Параметр | Традиційні методи | Comprehensible Input + MovaReader |
|---|---|---|
| Фокус | Правила та вправи | Розуміння реального контексту |
| Мотивація | Штучні діалоги | Справжні тексти, що цікавлять |
| Граматика | Зубріння таблиць | Інтуїтивне засвоєння |
| Афективний фільтр | Високий (стрес, оцінки) | Низький (читання у комфорті) |
| Результат | «Знаю правила, але не можу говорити» | Вільне розуміння та мовлення |
| Швидкість прогресу | Місяці на один рівень | Вимірюваний прогрес щотижня |
Крашен часто наводить приклад: люди, які багато читають цільовою мовою, стабільно перевершують тих, хто проходить граматичні курси — в тестах на граматику, лексику і навіть письмо. Парадокс? Ні. Логіка comprehensible input.
Практичний план: як застосувати гіпотезу Крашена прямо зараз
Крок 1: Знайдіть контент, який вас ЦІКАВИТЬ
Не шукайте «навчальні матеріали». Шукайте те, що ви читали б рідною мовою: новини, блоги, книги, статті. В нашому каталозі статей ви знайдете різноманітні тексти різних рівнів складності.
Крок 2: Завантажте текст у MovaReader
Будь-яку статтю з інтернету, будь-яку книгу. Один клік — і текст стає вашим особистим підручником з миттєвими AI-поясненнями.
Крок 3: Читайте, не зупиняючись
Не зупиняйтесь на кожному слові. Читайте потоком. Торкайтесь лише тих слів, без яких не зрозумілий загальний сенс. Це і є формула i+1 у дії.
Крок 4: Тренуйте засвоєне
Після читання переходьте до тренажерів фраз та друку фраз — щоб перевести пасивне знання в активне.
Крок 5: Повторюйте щодня, хоча б 15 хвилин
Систематичність важливіша за обсяг. 15 хвилин щоденного читання зрозумілого контенту ефективніші за 3 години зубріння раз на тиждень. Дослідіть наші тренажери, щоб зробити навчання різноманітним.
Критика Крашена та чому вона не скасовує comprehensible input
Філософська чесність вимагає визнати: теорію Крашена критикують. Основні аргументи:
- «Неможливо виміряти i+1» — так, точний рівень визначити складно. Але MovaReader вирішує цю проблему: будь-який текст стає зрозумілим завдяки AI-перекладу, тому питання точного рівня відпадає.
- «Output теж важливий» — Мерріл Свейн та інші лінгвісти стверджують, що практика мовлення (output) теж сприяє засвоєнню. Крашен не заперечує цього повністю, але вважає input первинним.
- «Потрібен і свідомий аналіз» — для деяких аспектів мови (наприклад, формальне письмо) свідоме знання правил корисне. Але для базового вільного володіння — input залишається фундаментом.
Важливо розуміти: жоден критик не заперечує, що читання та слухання зрозумілого матеріалу є надзвичайно ефективним. Суперечки точаться лише про те, чи це єдиний шлях. А для практики це не так важливо: навіть якщо comprehensible input — не єдиний метод, він точно найефективніший.
Старі методи проти нового підходу: контраст, який неможливо ігнорувати
Уявіть два сценарії.
Сценарій A (традиційний): Ви сідаєте за підручник. Читаєте правило про Past Perfect. Робите 20 вправ на заповнення пропусків. Отримуєте 18 з 20. Закриваєте підручник. Через тиждень — не можете пригадати, коли використовувати Past Perfect у реальному тексті.
Сценарій B (comprehensible input + MovaReader): Ви відкриваєте статтю BBC про історичну подію. Зустрічаєте Past Perfect у живому контексті: «By the time rescuers had arrived, the village had already been evacuated.» Торкаєтесь речення — AI пояснює структуру. Ви бачите, розумієте і відчуваєте, навіщо тут Past Perfect. Через тиждень — ви впізнаєте і використовуєте його інтуїтивно.
Різниця? У сценарії A ви вивчили правило. У сценарії B ви його засвоїли. Крашен аплодує стоячи.
Мова — це не набір правил. Це навичка, яка формується через масовий контакт зі зрозумілим контентом. І MovaReader — це найпотужніший інструмент у світі для створення такого контакту.
Базова підписка — лише €1/місяць. А Premium за €5/місяць включає всі поточні та майбутні тренажери, пріоритетну підтримку та можливість замовляти власні файли.
Почніть сьогодні. Оберіть будь-який текст. Зробіть його зрозумілим. І дозвольте своєму мозку робити те, що він робить найкраще — засвоювати мову природно.
Спробуйте демо-тренажер друку, щоб відчути, як працює навчання через контекст — без реєстрації, безкоштовно.
Вивчайте мови читаючи!
Спробуйте MovaReader всього за €1 — читайте тексти з миттєвим перекладом та інтерактивним тренуванням слів.
Спробувати за €1